Fachartikel
KI Landschaft Q2 2026 - ein ÜberblickDie KI-Landkarte hat sich verschoben
– und kaum jemand redet drüber
Eine Bestandsaufnahme der globalen KI-Landschaft 2026
Wer 2024 nach „KI" fragte, dachte an OpenAI. Punkt. Vielleicht noch Anthropic, wenn man's etwas tiefer nahm. Zwei Jahre später ist die Welt eine andere – und das hat Konsequenzen, die in deutschen Vorstandssitzungen noch nicht angekommen sind.
Wer in den letzten Monaten aufmerksam war, hat es bemerkt: Was als US-Monopol begann, ist heute ein globaler Wettlauf. China holt nicht mehr auf – China ist auf vielen technischen Dimensionen gleichgezogen oder vorbei. Europa hat Champions, von denen außerhalb der Tech-Szene niemand weiß. Indien baut eine eigene KI-Souveränität auf. Russland spielt sein eigenes Spiel. Und der spannendste Schauplatz ist gerade nicht Sprachverarbeitung, sondern Bildgenerierung – wo deutsche Tech am stärksten ist.
Zeit für eine Bestandsaufnahme. Ohne Marketing-Folien, ohne Zukunftsmusik, ohne den üblichen „Wir-müssen-jetzt"-Reflex.

Abbildung 1: Die sechs großen Cluster der globalen KI-Landschaft 2026
Die Ausgangslage: Vom Monopol zum Mehrkampf
Der ChatGPT-Moment Ende 2022 hat eine Kettenreaktion ausgelöst, deren Geschwindigkeit selbst optimistische Beobachter überrascht hat. OpenAI hatte ungefähr 18 Monate Vorsprung – diese Lücke ist heute geschlossen. Nicht nur von Anthropic und Google, sondern von einer Handvoll Akteuren, die 2022 noch nicht oder kaum existierten.
Drei Treiber sind verantwortlich:
Erstens sind die Trainingskosten kollabiert. Was OpenAI für GPT-4 noch im niedrigen Milliardenbereich gekostet hat, schaffen heute kleine Teams für einen Bruchteil. DeepSeek hat das spektakulär demonstriert. Die Folge: Eintrittsbarriere gefallen, Wettbewerb explodiert.
Zweitens hat Open Source gewonnen. Meta mit Llama, Mistral mit ihrer Mixtral-Reihe, DeepSeek, Qwen, Hunyuan – die meisten ernstzunehmenden Modelle sind heute öffentlich verfügbar. Wer ein eigenes LLM betreiben will, hat eine ganze Auswahl. Das war 2023 noch undenkbar.
Drittens wird der Markt fragmentierter, nicht konzentrierter. Statt eines Gewinners gibt es ein Dutzend Spezialisten – jedes Modell ist in einer anderen Disziplin Klassenbester.
Eine wichtige Klarstellung vorweg: Modell ist nicht gleich Produkt
Bevor wir in die Länderkarte einsteigen, eine Begriffsklärung, ohne die das ganze Bild verzerrt wird.
In der medialen Berichterstattung werden „Modell" und „Produkt" oft synonym verwendet. Das führt regelmäßig zu Verwirrung. Microsoft Copilot ist beispielsweise kein KI-Modell – es ist ein Funktions- und Integrations-Baustein, der je nach Variante (Microsoft 365 Copilot, GitHub Copilot, Copilot Studio, Security Copilot) verschiedene Modelle unter der Haube nutzen kann. Aktuell überwiegend GPT-Modelle von OpenAI, perspektivisch zunehmend auch Anthropic-Modelle und eigene Microsoft-Modelle wie MAI. Wenn du morgen liest „Microsoft wechselt Copilot von OpenAI auf Anthropic", wechselt nicht das Produkt – es wechselt das Modell unter der Haube. Das Produkt heißt weiter Copilot, die Oberfläche bleibt gleich, die Lizenz auch.

Abbildung 2: Schichtenmodell – Anwender, Produkt und Modell sind drei verschiedene Ebenen
Das gleiche Muster bei vielen anderen großen Anbietern: ChatGPT (Produkt) ist nicht GPT-5 (Modell). Le Chat (Produkt) ist nicht Mistral Large (Modell). Gemini (Produkt) ist nicht Gemini 2.5 Pro (Modell) – auch wenn der Name es nahelegt. Diese Trennung ist mehr als akademisch: Sie bestimmt Einkaufsstrategie, Vertragsverhandlungen und technische Architektur. Wer nur das Produkt im Blick hat, übersieht, dass die eigentliche Wertschöpfung – und das eigentliche Risiko – beim Modell liegt.
Praxis-Hinweis für Einkauf und IT-Strategie Verträge sollten Modell-Wechsel adressieren – nicht nur das Produkt-Label. Risikoanalysen müssen die Modell-Schicht berücksichtigen, weil Verhalten und Halluzinationsmuster sich beim Modellwechsel ändern können. KI-Governance braucht ein Inventar auf Modell-Ebene, nicht nur ein Produkt-Inventar. |
|---|
In diesem Artikel reden wir primär über die Modelle. Die Produkte wechseln häufiger den Hersteller als ihre Anwender es merken.
USA: Immer noch Maßstab, aber nicht mehr Monopol
OpenAI, Anthropic, Google und Meta dominieren weiterhin die internationale Wahrnehmung. Bei Sprachmodellen sind Claude, GPT und Gemini der Industriestandard für Premium-Anwendungen. Bei Bildgenerierung halten Midjourney (Aesthetik), GPT Image (Text in Bildern) und Imagen (Produktfotografie) ihre Nischen.
Aber: Die Margen sinken, der Lock-in-Effekt schmilzt. Wer heute eine RAG-Anwendung baut, wechselt zwischen Anbietern wie früher zwischen Datenbank-Treibern. Die API-Preise für Bildgenerierung sind in 18 Monaten um den Faktor 25 bis 40 gefallen – von etwa 10 Cent pro Bild auf wenige Zehntel Cent. Das verändert die Geschäftsmodelle der Anbieter fundamental.
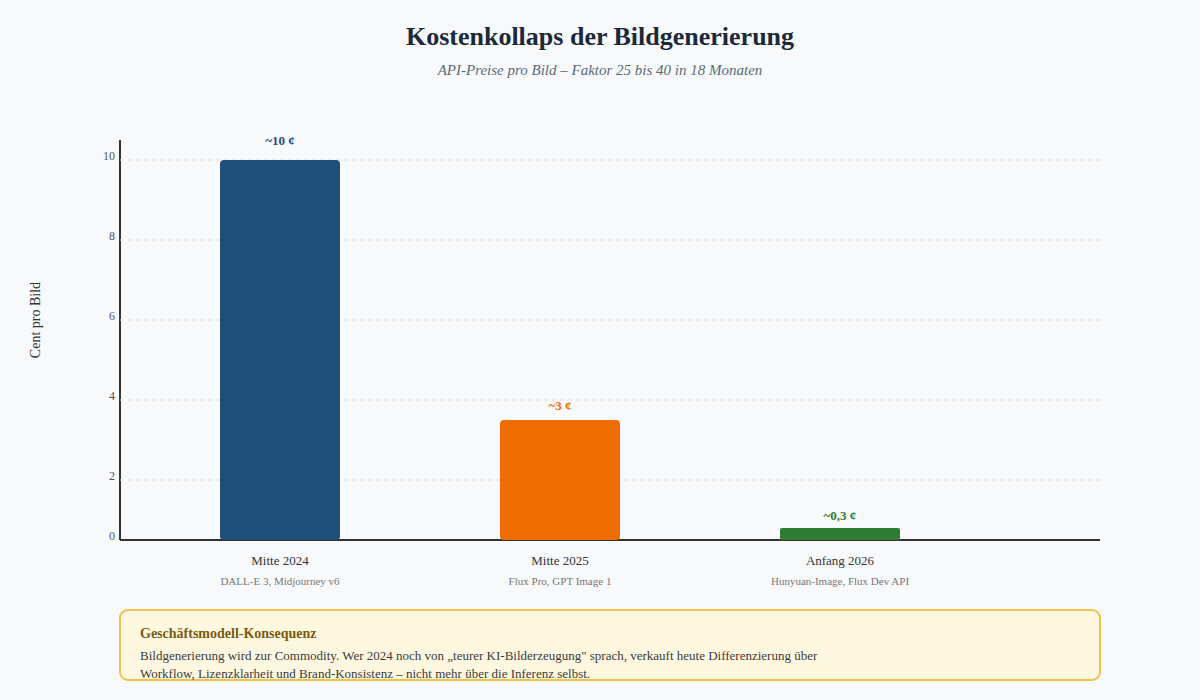
Abbildung 3: Kostenkollaps der Bildgenerierung – Faktor 25 bis 40 in 18 Monaten
Bemerkenswert: Adobe Firefly hat sich als Nische etabliert, weil es das einzige Bildmodell mit klarer Copyright-Indemnifizierung ist – nur auf lizenzierten Daten trainiert. Für Marketing-Abteilungen großer Konzerne ein entscheidendes Argument. Wer rechtssichere Bilder braucht, geht zu Adobe. Wer optisch beeindrucken will, zu Midjourney. Wer beides will, zahlt zweimal.
Europa: Zwei Champions, die kaum jemand kennt
Frankreich hat Mistral. Das ist bekannt. Mistral Large und die Mixtral-Modelle sind technisch konkurrenzfähig, der Le-Chat-Assistent etabliert sich in europäischen Behörden und einigen DAX-Konzernen, weil er das „europäische Häkchen" auf der Compliance-Folie liefert. Faire Einschätzung: Mistral ist kein technischer Außenseiter, aber auch kein Vorreiter. Mit OpenAI, Anthropic und DeepSeek mithalten – ja. Sie überholen – nein.
Der zweite Champion sitzt in Deutschland und ist die größte ungenutzte Marketing-Gelegenheit der deutschen Wirtschaft: Black Forest Labs. Aus dem ehemaligen Kernteam von Stable Diffusion hervorgegangen, mit Sitz in Freiburg. Ihre Flux-Modellfamilie führt aktuell mehrere Bildgenerierungs-Benchmarks an – speziell bei Photorealismus. Ex-Stable-Diffusion-Team bedeutet: Diese Leute haben den ganzen Bereich miterfunden. Flux Pro liefert Bilder, die von echten Fotos optisch nicht zu unterscheiden sind, mit kameraspezifischen Eigenschaften wie Schärfentiefe und Linsenverzerrung auf Knopfdruck.

Abbildung 4: Die drei Lizenzstufen von Flux – „Open" heißt nicht automatisch „kommerziell frei"
Wichtig zur Lizenzlage, weil hier viel durcheinandergeht: Black Forest Labs fährt ein gestaffeltes Modell. Flux Pro ist die kommerzielle Premium-Variante – nur über API oder Lizenz nutzbar, nicht frei. Flux Dev ist offen verfügbar und lokal lauffähig, aber die Lizenz erlaubt explizit keine kommerzielle Nutzung – nur Forschung und private Experimente. Wer Flux Dev kommerziell einsetzen will, braucht eine separate Lizenz von Black Forest Labs. Flux Schnell ist die einzige Variante unter wirklich offener Apache-2.0-Lizenz – kommerziell frei nutzbar, aber qualitativ schwächer und auf Geschwindigkeit optimiert.
Lizenz-Falle in der Praxis Eine Marketingabteilung, die Flux Dev lokal auf einer Workstation laufen lässt und damit Kampagnen-Bilder erzeugt, begeht eine Lizenzverletzung – unabhängig davon, wie wenig „kommerziell" sich die Nutzung anfühlt. Wer es richtig macht, lizenziert Flux Pro oder Flux Dev kommerziell. Beides läuft auch auf eigenem Hosting, beides ist DSGVO-tauglich, beides bleibt im eigenen Rechenzentrum. |
|---|
Dass Black Forest Labs in Deutschland fast unbekannt ist, während jedes Mittelstandsmagazin über DALL-E schreibt, ist symptomatisch. Wir haben einen Weltmarktführer im Land – im Schwarzwald – und niemand redet drüber. Das ist nicht nur PR-mäßig schade, sondern strategisch bitter: Wenn deutsche Unternehmen eine souveräne, lokal betreibbare Bildgenerierung suchen, müssen sie das Rad nicht neu erfinden. Es liegt 200 Kilometer entfernt.
China: Vom Imitator zum Innovator – mit beachtlichem Tempo
Die deutlichste Veränderung der letzten 24 Monate. Chinesische Modelle sind nicht mehr „auch da", sie sind in mehreren Disziplinen führend.
DeepSeek hat die Welt mit V3 und R1 schockiert: Reasoning-Performance auf GPT-Niveau zu einem Bruchteil der Trainingskosten. Open Source. Das hat ganze Investitionskalkulationen in den USA infrage gestellt.
Qwen von Alibaba ist eines der meistgenutzten Open-Source-Modelle weltweit – nicht nur in China. Wer auf Hugging Face nach einem fähigen, offen verfügbaren LLM sucht, landet sehr oft bei Qwen.
Hunyuan von Tencent betreibt mit der Image-3.0-Serie das größte Open-Source-Bildmodell der Welt – 80 Milliarden Parameter, autoregressiv, mit überlegenem „Welt-Wissen" im Bildkontext.
Seedream von ByteDance (TikTok-Mutter) bringt das visuelle Gespür der Plattform ins Modell – führend bei künstlerischen Inhalten und Asien-spezifischen Motiven.
Kling kombiniert Bild und Video in einer durchgehenden Pipeline und konkurriert direkt mit OpenAIs Sora.
Was das praktisch bedeutet: Wer eine Anwendung baut und auf maximale Kosten-Nutzen-Effizienz schielt, kommt an chinesischen Open-Source-Modellen kaum noch vorbei. Die Modelle laufen lokal, die Lizenzen sind großzügig, die Qualität stimmt. Compliance-technisch ist das eine andere Frage – aber technisch sind chinesische Modelle 2026 Weltklasse.
Russland: Regional stark, international irrelevant
Yandex hat ein eigenes LLM-Ökosystem mit YandexGPT und dem Sprachassistenten Alice. Sberbanks GigaChat ist im russischen Banken- und Behördensektor verbreitet. Beide Modelle sind in ihrem Sprachraum konkurrenzfähig, außerhalb davon faktisch nicht existent.
Für deutsche Unternehmen ist Russlands KI-Landschaft eine Fußnote – sanktionsbedingt und marktbedingt. Interessant höchstens als Indikator, dass jeder größere Sprachraum mittlerweile sein eigenes Modell baut, weil Sprachmodelle ohne Sprachpräsenz im Trainingsmaterial einfach schlecht sind.
Indien: Eigene Liga, eigener Pfad
Indien geht einen bemerkenswerten Weg. Statt mit OpenAI zu konkurrieren, baut die indische KI-Szene gezielt für die eigene Realität: 22 Amtssprachen, Niedrigbandbreiten-Netze, mobile Endgeräte, Behörden- und Bildungsanwendungen.
Krutrim (Ola), Sarvam AI, BharatGPT (CoRover), Hanooman (IIT Bombay/Reliance) und Project Indus (Tech Mahindra) haben jeweils Schwerpunkte auf indische Sprachen, kulturelle Kontexte und schlanke Inferenz auf günstigen Geräten. Sarvam wird von der indischen Regierung im Rahmen der „IndiaAI Mission" gefördert.
Frugal Innovation in Reinform – aus der Not geboren, aus dem Mangel an Compute-Ressourcen. Das Ergebnis sind Modelle, die zwar nicht GPT-5 schlagen, aber für ihre Zielgruppe – 1,4 Milliarden Inder mit 22 Sprachen und durchwachsener Internet-Anbindung – exakt das Richtige tun.
Lehrstück für Europa KI-Souveränität ist nicht „wir bauen unser eigenes GPT-5". KI-Souveränität ist „wir bauen, was wir wirklich brauchen". Das verstehen die Inder. Wir noch nicht. |
|---|
Israel, Japan, Taiwan: Die Spezialisten
Drei Tech-Nationen, die in der medialen KI-Berichterstattung kaum auftauchen, aber strategisch hochrelevant sind – jede aus einem anderen Grund.
Israel – die heimliche KI-Macht des Westens
Tel Aviv hat eine Dichte an KI-Forschern und -Startups, die international höchstens noch das Silicon Valley übertrifft. Das prominenteste Unternehmen ist AI21 Labs, mitbegründet von Amnon Shashua (dem Mann hinter Mobileye), heute mit 1,4 Milliarden Dollar bewertet und über 336 Millionen Dollar an Funding eingesammelt – Investoren sind unter anderem Nvidia, Google und Intel Capital. Ihr Modell Jamba kombiniert Transformer- und Mamba-Architektur, kann 256.000 Token Kontext verarbeiten und ist als offenes Modell verfügbar.
Kunden sind Boston Consulting Group, Bain, Moderna, Booking.com – also genau die Liga, in der auch europäische Konzerne unterwegs sind. Im März 2025 haben sie Maestro vorgestellt, ein Orchestrierungssystem für KI-Workflows, das Multi-Modell-Architekturen industriell beherrschbar macht. Dazu kommen Dutzende weiterer israelischer Player im militärischen, Cybersecurity- und Enterprise-Umfeld – ein Ökosystem mit unverhältnismäßig viel Substanz für ein Land mit zehn Millionen Einwohnern.
Japan – Spezialisierung statt Größenwahn
Japan geht einen Weg, den deutsche Mittelständler studieren sollten. Statt einem Modell, das alles können soll, baut Japan über 30 spezialisierte LLMs – jedes für einen klar abgegrenzten Anwendungsfall. NTTs „tsuzumi 2" (30 Milliarden Parameter, läuft auf einer einzigen H100-GPU für rund 35.000 Dollar Hardwarekosten) ist auf 40 Jahren NLP-Forschung von NTT aufgebaut und für japanischen Sprachgebrauch optimiert.
Fujitsu Takane wird in Behörden eingesetzt – im Februar 2026 hat Fujitsu bekanntgegeben, dass die Auswertung öffentlicher Konsultationen, die früher einen Monat gedauert hat, jetzt automatisiert läuft. Sakana AI, gegründet von einem der Co-Autoren des „Attention Is All You Need"-Papers (also einem der Erfinder der Transformer-Architektur), entwickelt mit „Evolutionary Model Merge" eine Methode, neue Modelle ohne klassisches Training zu erzeugen.
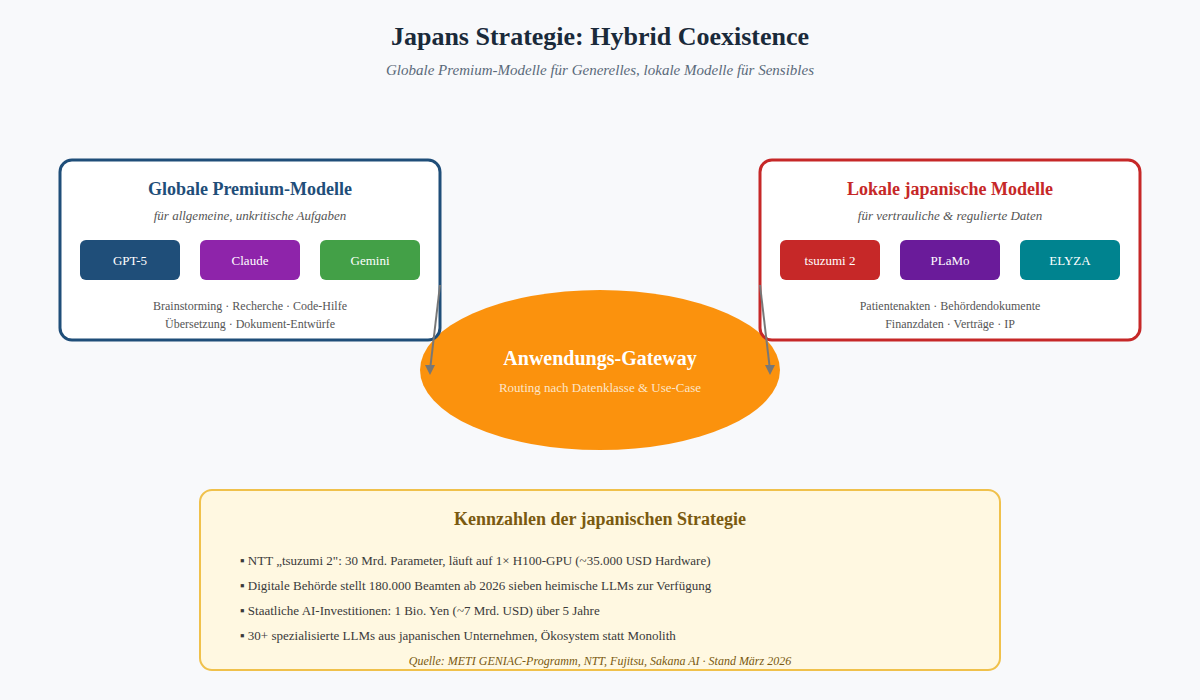
Abbildung 5: Japans „Hybrid Coexistence" – globale Modelle für Generelles, lokale für Sensibles
Die japanische Regierung hat im Dezember 2025 eine Billion Yen (rund sieben Milliarden Dollar) über fünf Jahre für KI und Halbleiter zugesagt und ihre Digitalbehörde stellt 180.000 Beamten ab 2026 sieben verschiedene japanische LLMs zur Verfügung. Die Strategie heißt „hybrid coexistence" – globale Modelle für allgemeine Aufgaben, japanische Modelle für vertrauliche Daten und regulierte Branchen. Klingt vernünftig. Wäre auch ein gangbarer Weg für Deutschland.
Taiwan – wer die Hardware kontrolliert, baut auch die Modelle
Foxconn (Hon Hai) hat im März 2025 FoxBrain vorgestellt – das erste LLM speziell für Traditionelles Chinesisch, basierend auf Llama 3.1 mit 70 Milliarden Parametern. Trainiert in vier Wochen auf 120 Nvidia-H100-GPUs, optimiert für Fertigung, Supply-Chain-Management und Entscheidungsunterstützung. Die Botschaft dahinter ist deutlich: Selbst Hardware-Hersteller bauen sich heute eigene LLMs, weil generische Modelle für ihre Branche zu wenig hergeben.
Dass das ausgerechnet aus Taiwan kommt – wo TSMC die Chips für die gesamte globale KI-Industrie produziert – hat eine geopolitische Pointe. Wer die Hardware kontrolliert, kann auch die Modelle bauen. Die These „Wir kaufen die Hardware aus Asien, aber das Schlaue passiert in Kalifornien" wird brüchig.
Die gemeinsame Lehre dieser drei Nationen Spezialisierung schlägt Größe. Niemand muss einen GPT-5-Klon bauen, um KI-relevant zu sein. Wer ein klares Anwendungsgebiet, eine verteidigbare Sprach- oder Branchennische und genug Investitionswillen mitbringt, kann sich einen Platz an der Sonne sichern – auch ohne Hyperscaler-Budget. |
|---|
Bildgenerierung – wo es richtig spannend wird
Während alle über LLMs reden, verschiebt sich das wirtschaftliche Schwergewicht im Bildbereich rasant. Drei Beobachtungen:
Erstens ist Text-in-Bild gelöst. Bis 2024 sah jedes Marketingbild aus, als hätte ein Drittklässler die Buchstaben mit Wachsmalstiften nachgemalt. 2026 produzieren GPT Image, Ideogram und Z-Image typografisch korrekte Plakate, Schilder und Logos. Das ist eine stille Revolution für Marketing-Abteilungen – die Adobe-Stock-Datenbanken werden überflüssig.
Zweitens kollabiert die Differenz zwischen Cloud und lokal. Mit einer Consumer-Grafikkarte mit 16 GB VRAM können Sie heute Modelle laufen lassen, die Midjourney v6 ebenbürtig sind. Stable Diffusion 3.5, Hunyuan-Image und SDXL-Derivate lokal – das war vor zwei Jahren undenkbar. Auch Flux Dev läuft lokal, aber Achtung: nur unter Forschungs-/Privatlizenz, kommerziell braucht es Flux Pro oder eine separate Lizenz. Für datenschutzsensitive Anwendungen (Gesundheit, Recht, Behörden) ist lokale Inferenz trotzdem ein Game-Changer.
Drittens verschmelzen Bild und Video. Kling, Veo, Sora, Wan – die Pipeline „Bild generieren → genehmigen → in Bewegung versetzen" ist Standard. Marketing-Teams produzieren heute in einer Stunde, wofür sie vor zwei Jahren eine Werbeagentur und zwei Wochen brauchten.
Use-Case-Matrix Bildgenerierung
Use-Case |
Anbieter |
Lizenz / Modus |
Stärken |
|---|---|---|---|
Lizenzsichere Marketingbilder |
Adobe Firefly |
Kommerziell mit Indemnifizierung |
Rechtssicherheit, Konzern-tauglich |
Photorealismus Premium |
Flux Pro (Black Forest Labs) |
Kommerziell, deutsch |
Photoqualität, kameraspezifische Effekte |
Künstlerische Inhalte |
Midjourney, Seedream |
Subscription / API |
Aesthetik, Stilkonsistenz |
Text in Bild |
Ideogram, GPT Image 1 |
API |
Typografie, Logos, Plakate |
Lokale Souveränität |
Stable Diffusion 3.5, Hunyuan |
Open Source, kommerziell ok |
Datenkontrolle, eigenes Hosting |
Video-Generierung |
Kling, Sora, Veo, Wan |
API / Subscription |
Bewegtbild, Bild-zu-Video-Pipelines |
Konsequenz für deutsche Unternehmen: Die Frage ist nicht mehr „Brauchen wir Bildgenerierung?", sondern „Welcher Anbieter mit welcher Lizenz für welchen Use-Case?". Anders gesagt: Bildgenerierung ist 2026 ein Mehr-Modell-Thema, kein Ein-Tool-Thema.
Was das für deutsche Entscheider bedeutet
Drei strategische Konsequenzen, ungeschönt:
Erstens: Wer auf einen einzigen Anbieter setzt, hat verloren
Die Tage, in denen man „die ChatGPT-Lizenz" gekauft und damit das Thema KI abgehakt hat, sind vorbei. Eine reife KI-Strategie integriert mehrere Modelle nach Anwendungsfall. Multi-Modell-Architekturen sind 2026 Pflicht, nicht Kür.
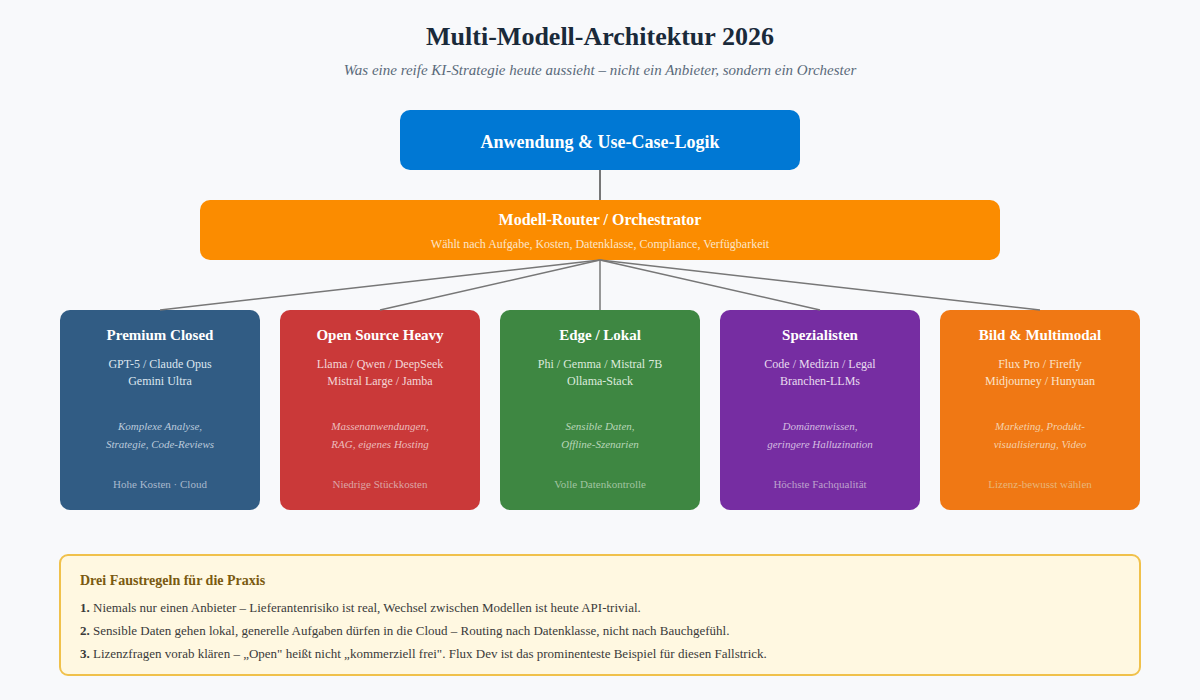
Abbildung 6: Multi-Modell-Architektur – Routing nach Aufgabe, Datenklasse und Compliance-Anforderung
Zweitens: Open Source ist eine reale Option
Wer Compliance-Sorgen hat, wer DSGVO ernst nimmt, wer den AI Act im Hinterkopf hat – für den ist die Frage „lokal vs. Cloud" nicht mehr ideologisch, sondern wirtschaftlich. Ein eigener Llama- oder Qwen-Server kostet einen Bruchteil der Cloud-Lösung, sobald die Lastspitzen regelmäßig werden. Die Werkzeuge dafür (vLLM, Ollama, ComfyUI) sind ausgereift.
Drittens: Die EU-Souveränitätsdiskussion läuft am Markt vorbei
Während Brüssel über AI-Act-Detailverordnungen verhandelt, kaufen deutsche Mittelständler entweder amerikanisch oder chinesisch ein. Mistral und Black Forest Labs sind technisch da – aber kommunikativ und kommerziell unterrepräsentiert. Die europäische Antwort wird nicht durch Regulierung geschaffen, sondern durch Sichtbarkeit, Adoption und Ökosystem-Aufbau. Daran hapert es.
Ausblick: Was 2027 wichtig wird
Drei Wetten, die ich abgeben würde:
Erstens: Multimodalität wird Standard. Die Trennung zwischen „Sprachmodell" und „Bildmodell" verschwindet. Ein einziges Modell beantwortet Fragen, generiert Bilder, analysiert Videos, schreibt Code. Die Trennung in Anbieter-Stacks wird historisch.
Zweitens: Edge-Inferenz explodiert. Modelle, die heute 80 GB VRAM brauchen, laufen 2027 auf Smartphones. Microsoft, Apple und Google rüsten ihre Betriebssysteme entsprechend auf. Lokale KI wird zum Default, Cloud-KI zur Spezialanwendung.
Drittens: Der Markt konsolidiert sich, aber anders als erwartet. Es wird nicht „einen Gewinner" geben. Es wird mehrere Cluster geben:
Cluster |
Beispiele |
Stärke |
|---|---|---|
US-Premium |
OpenAI, Anthropic, Google |
Spitzenqualität, Innovationsdruck |
China-Massenanbieter |
DeepSeek, Qwen, Hunyuan |
Kosteneffizienz, Open Source, Skala |
Europäische Spezialisten |
Mistral, Black Forest Labs |
Compliance, Souveränität (technisch) |
Nationale Champions |
AI21, NTT, Sakana, Foxconn |
Sprachraum & Branchen-Fokus |
Open-Source-Community |
Llama-Forks, Mistral, Phi |
Adaptierbarkeit, Vendor-Unabhängigkeit |
Regional-Player |
Krutrim, Sarvam, YandexGPT |
Lokalsprachen & Kultur-Fit |
Wer das alles im Blick behält, hat einen Wettbewerbsvorteil. Wer weiterhin glaubt, „KI" sei ein Synonym für ChatGPT, wird in 24 Monaten erstaunt sein, wie schnell sich der Markt unter ihm wegbewegt hat.
Zusammengefasst Die KI-Welt 2026 ist polyzentrisch, nicht monopolistisch. Modelle und Produkte sind verschiedene Schichten – beide brauchen eigene Strategien. Open Source ist keine Spielwiese mehr, sondern Mainstream im Enterprise-Stack. Bildgenerierung ist der spannendste und schnellste Schauplatz, mit deutscher Spitze. Spezialisierung schlägt Größe – die Lehre aus Israel, Japan, Taiwan, Indien. Multi-Modell-Architekturen sind 2026 Pflicht. Wer nur einen Anbieter hat, hat ein Risiko. |
|---|
Zur Person
Ulrich Boddenberg berät seit über drei Jahrzehnten Unternehmen zu Microsoft-Technologien und seit einigen Jahren auch zu praktischen KI-Anwendungen. Schwerpunkte: Microsoft 365, SQL Server, SharePoint, Copilot – und reproduzierbare KI-Bildgenerierung in Kundenprojekten. Aktuelle Buchprojekte: „SQL Server in der Praxis" (5 Bände), „Microsoft Copilot für Entscheider".
boddenberg.de · IT-Consulting · Software Engineering · Technologieseminare